아키텍처 및 워크플로우
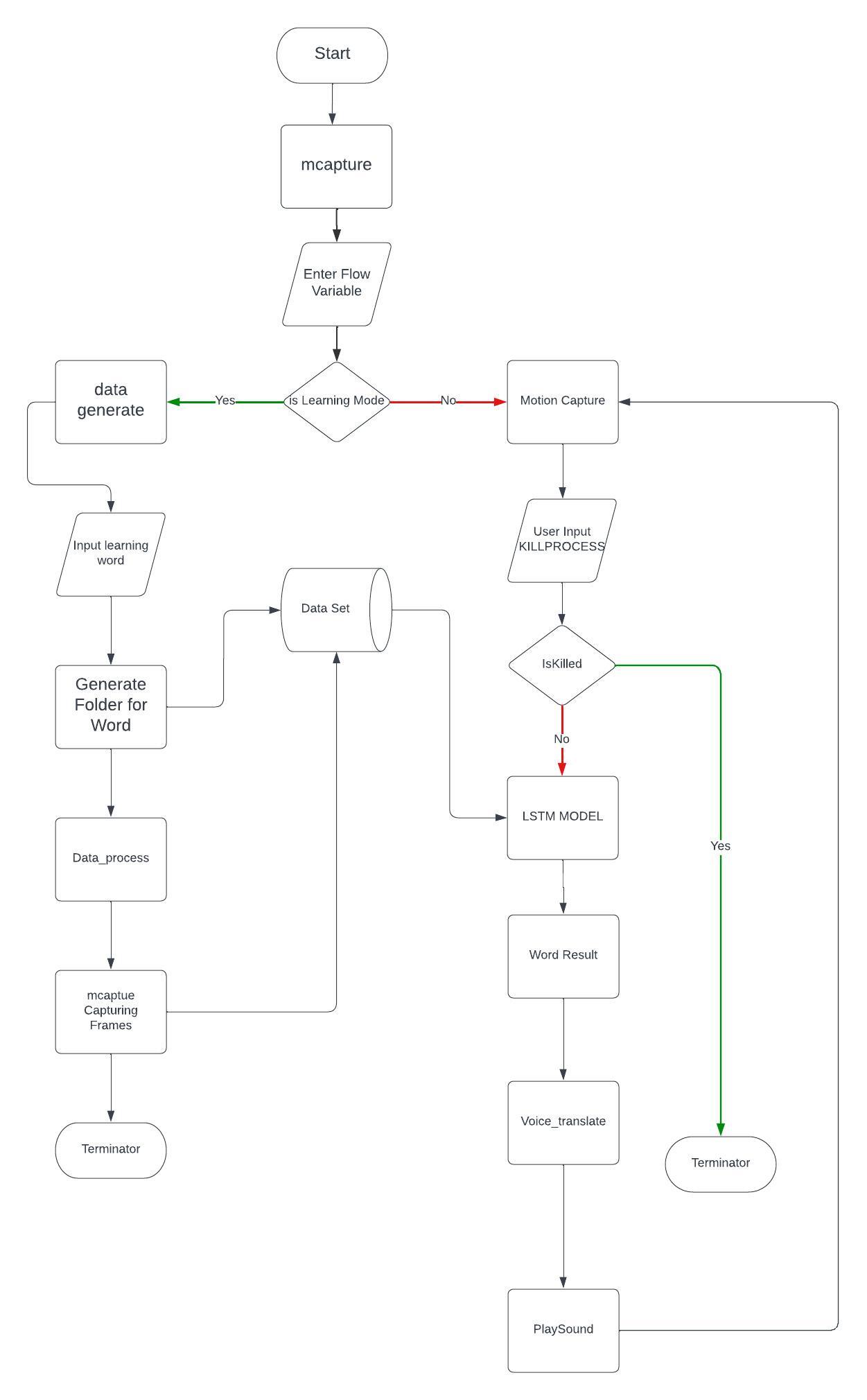
High Level Diagram
상위 수준의 시스템 구조를 나타낸 다이어그램입니다.
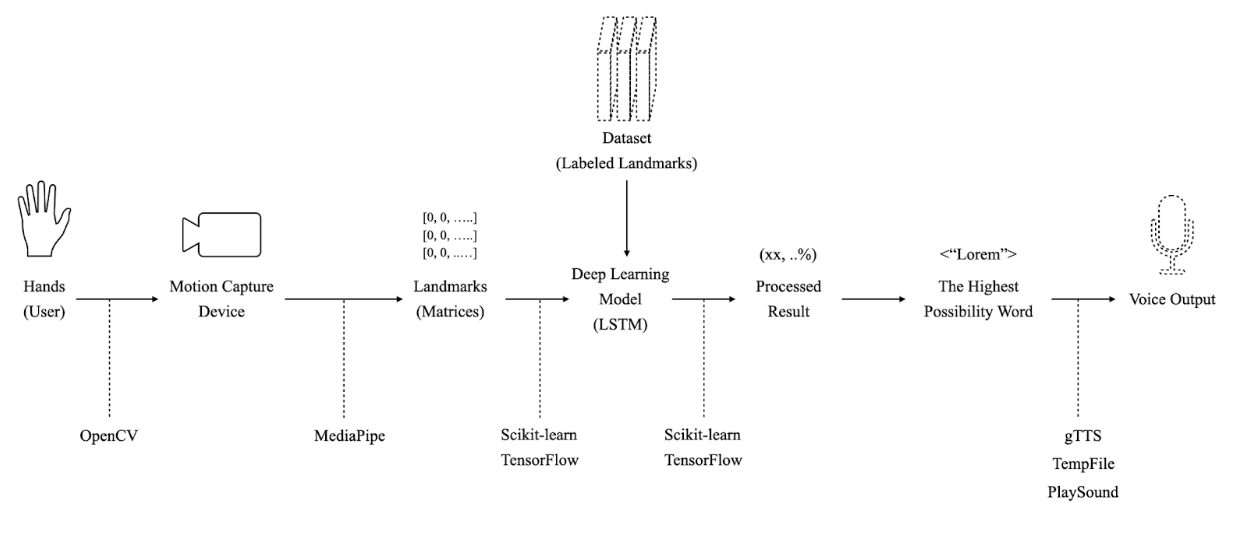
Workflow
시스템의 동작 과정 및 데이터 흐름을 시각적으로 설명한 워크플로우입니다.
본 프로젝트는 깊이 있는 학습 기법 중 하나인 LSTM(Long Short-Term Memory) 신경망을 활용하여, 수화 제스처를 실시간 음성으로 변환하는 시스템을 개발하는 것을 목표로 합니다. 이를 통해 청각 장애인과 비장애인 사이의 소통 격차를 줄이고, 모두가 보다 원활하게 소통할 수 있도록 돕고자 합니다.
시스템은 카메라나 센서를 통해 사용자의 수화 제스처를 실시간으로 캡처합니다. 캡처된 영상은 LSTM 기반의 행동 인식 모델을 통해 분석되며, 이 모델은 다양한 정적 및 동적 제스처를 학습하여 인식할 수 있도록 설계되었습니다. LSTM 네트워크는 시퀀스 데이터의 시간적 의존성을 효과적으로 모델링하여 수화의 동적인 특성을 잘 반영합니다.
인식된 제스처는 텍스트 정보로 변환된 후, 텍스트-투-스피치(TTS) 기술을 이용해 음성으로 합성됩니다. 합성된 음성은 스피커나 헤드폰을 통해 출력되어, 수화를 모르는 사람들과도 원활한 소통이 가능하도록 합니다.
실시간 수화 인식: 지연 없이 즉각적으로 제스처를 인식하여 소통이 원활합니다. 다중 제스처 인식: 정적 제스처와 동적 제스처 모두를 인식할 수 있도록 학습되었습니다. 정확성과 견고성: 다양한 환경과 조명 조건에서도 높은 정확도를 유지할 수 있도록 다양한 데이터셋을 활용해 학습하였습니다. 접근성: 수화 숙련도에 상관없이 누구나 쉽게 사용할 수 있도록 설계되었습니다.
이러한 시스템은 청각 장애인 및 난청인들이 사회적, 직업적 환경에서 신뢰할 수 있는 소통 수단을 제공받도록 지원하며, 깊이 있는 학습 기법과 LSTM 네트워크의 역량을 통해 소통의 장벽을 허무는 것을 목표로 합니다.
상위 수준의 시스템 구조를 나타낸 다이어그램입니다.
시스템의 동작 과정 및 데이터 흐름을 시각적으로 설명한 워크플로우입니다.
LSTM은 인공 신경망의 한 종류로, 시퀀스 데이터를 입력받아 원하는 출력을 생성하는 모델입니다. 기존의 순환 신경망(RNN)은 장기 의존성 문제를 가지고 있었으나, LSTM은 셀 상태(cell state)라는 구조를 도입해 이 문제를 효과적으로 해결하였습니다. 셀 상태는 네트워크의 여러 시점에 걸쳐 정보를 유지하고 전달하여, 장기간의 데이터를 기억할 수 있도록 합니다.
데이터 수집: OpenCV API를 이용해 카메라로 30프레임의 데이터를 수집합니다.
데이터 전처리: MediaPipe를 활용하여 얼굴, 왼손, 오른손, 그리고 몸의 좌표값(총 1662개)을 추출하고, 이를 NumPy 배열로 전처리합니다.
학습: 전처리된 데이터를 바탕으로 LSTM 모델을 200 epochs 동안 훈련하며, 전체 훈련 과정을 30회 반복합니다.
action.keras 파일에 저장됩니다.LSTM은 자연어 처리, 음성 인식, 제스처 인식 등 다양한 분야에서 우수한 성능을 보여온 모델입니다. 그 장점으로는 시퀀스 데이터 처리 능력과 장기 의존성 문제 해결 능력이 있으나, 단점으로는 모델 복잡도가 높아 학습 시간과 연산 자원이 많이 소요될 수 있다는 점이 있습니다.
현재 다른 모델(예: Transformer, 합성곱 신경망, 양방향 LSTM)도 고려 중이나, 우선 기본 데모 단계에서는 LSTM을 사용해 mac 환경에서 dmg 파일로 배포하는 수준에 도달했습니다. 다만, 정확도 향상을 위해 프레임 수, 예측 임계값 등의 최적화 작업이 추가로 필요하며, TensorFlow Keras 대신 PyTorch를 사용할 경우 동적 계산 그래프의 장점을 활용할 수 있을 것으로 예상됩니다.